The Beginner's Guide to Database Relationships

No matter your business type, you probably collect vast amounts of data. And if you’ve ever tried to do something with it (such as analyze or visualize it), you probably know that in its raw form, data is pretty much useless.
Consider raw data as wheat, clean data as flour, and analyzed and visualized data as freshly baked bread. To go from unstructured bits of data to something that can be further used in BI tools, you need a vast number of processes and tools. One of them is something called database relationships.
Today, we’re going to show you what they are and why they matter in a tutorial on database relationships for beginners.
Understanding these relationships is also the foundation for modern analytics tools like Luzmo Studio, which rely on well-structured data to power dashboards, and AI assistants like Luzmo IQ and Luzmo AI, which help users explore and analyze data faster without needing deep database expertise.
What are database relationships?
Database relationships are the associations between different tables in a relational database. In a relationship database management system (RDBMS or DBMS), data is organized into tables. The relationships between these tables determine how the data in one table is connected to the data in the other table.
To understand database and table relationships, and how they fit into data modeling and schema design, we need to define a few key terms first.
The primary key: the unique identifier for each record in a table, ensuring that each row in a table is uniquely identified.
The foreign key: this is the field in the second table that connects to the primary key in the first table. It determines the link between the two tables. The foreign key establishes referential integrity, making sure that the relationships between two tables are valid.
Referential integrity: this ensures that the fields in the table from the foreign key correspond to fields in the table from the primary key. If the foreign key does not correspond to an appropriate primary key or the value is null, the referential integrity is violated.
Normalization: database relationships play a huge part in data normalization. They help organize the data in such a way that redundancy and dependency are reduced.
Important note: there are many different ways to model your data and build relationships in a database. However, not all of them are ideal for an analytics use case. The database relationships we’re about to show you are ideal for production databases and building a great foundation for your app.
For analytics use cases, such as embedded analytics, this is not the ideal structure because you would need a single dataset for all operations.
Why are database relationships important?
If you do database design and management and you want to prepare data for future analysis and visualization, database relationships should be of utmost importance to you. Here are a few key reasons.
Data integrity
Database relationships define the rules and constraints for data, which ensures integrity and maintenance of relationships between tables. With higher data integrity, there is a lower risk of data inconsistencies or orphaned data.
More efficient data retrieval
When database relationships are defined, the database joins related tables. This means that you can show and combine data across different tables in one result set. Consequently, this means faster querying and no redundancy when you store data.
Normalization
Database normalization is a key part of preparing data for further analysis and visualization. Having relationships between databases fosters normalization as larger tables are broken down into smaller ones which are easier to store and maintain.
Flexibility in querying
When relationships are established between database tables, it’s easier to retrieve specific information by searching through related tables. This also makes it effortless to extract more meaning from your data.
Scalability
The bigger your relational database, the more important it is to have established relationships. When ground rules are clearly set up, you can add large data volumes without changing much of the data structure.
Simplified maintenance
Want to make changes to one child table without affecting the entire database? You can do that with proper database relationships, which speeds up querying and makes your entire database more modular. Utilizing Liquibase, you can ensure seamless management of these relationships, allowing for precise adjustments to individual tables while maintaining the integrity of your database architecture.
Enforcing business rules
By default, database tables with clearly defined relationships enforce business rules. But once you set them up, they are set up for good, which means that new data has to meet certain conditions and requirements to even be added to the database.
The different types of relationships
There are three main types of relationships between tables in databases: one-to-one, one-to-many and many-to-many. To best understand which relationship type is being used, you first need to understand the data, the tables, and the business rules behind them.
If you’re creating tables in a database like MySQL or SQL Server, you can define these relationships when building tables, using primary and foreign keys.
One-to-one database relationship
In this type of relationship, tables on both ends have only one record and every primary key value relates to none or one record in the related table.

One-to-one relationships are commonly forced by business rules and they don’t flow naturally from the data. These types of relationships are not very common in practice for one reason: it may be more practical to combine the two tables into one.
Example: two sets of tables. Table A has customer names and table B has customers’ contact information. Each entry in the first table corresponds to only one field in the second table.
One-to-many database relationship
Every record in the first table can have multiple corresponding records in the second table. However, every record in the second table corresponds to only one in the first table. A one-to-many relationship is the most common type of database relationship in modern databases.
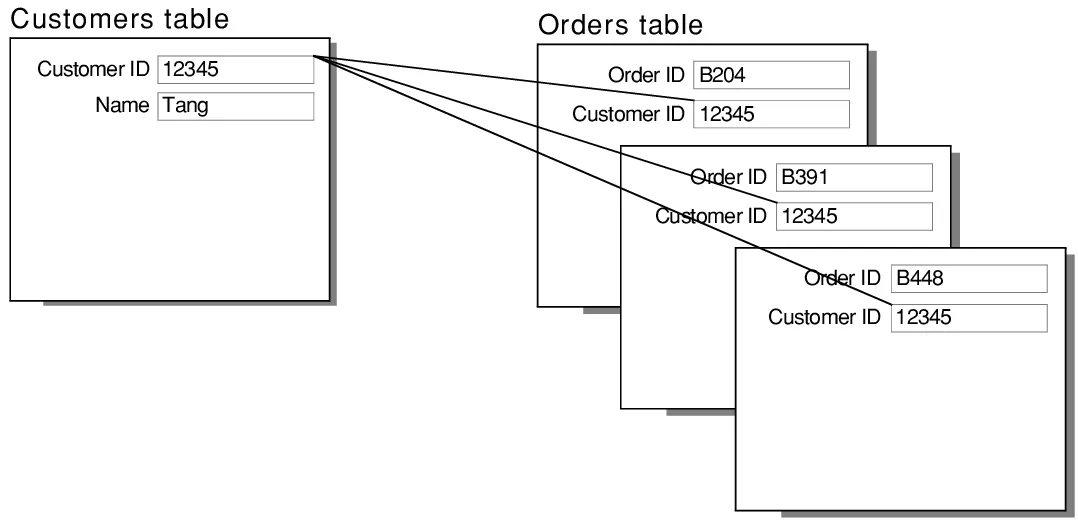
Example: one database table has basic information about your customers. The other database has their orders. The orders table can have multiple orders for one customer. In the customers table, those multiple orders can only be linked to one customer at a time.
Many-to-many database relationship
Many-to-many relationships are the most complex of the three. In this case, every record in the first table can have multiple corresponding records in the second table. To use many-to-many relationships, it’s necessary to introduce a third table, called a junction table or linking table.
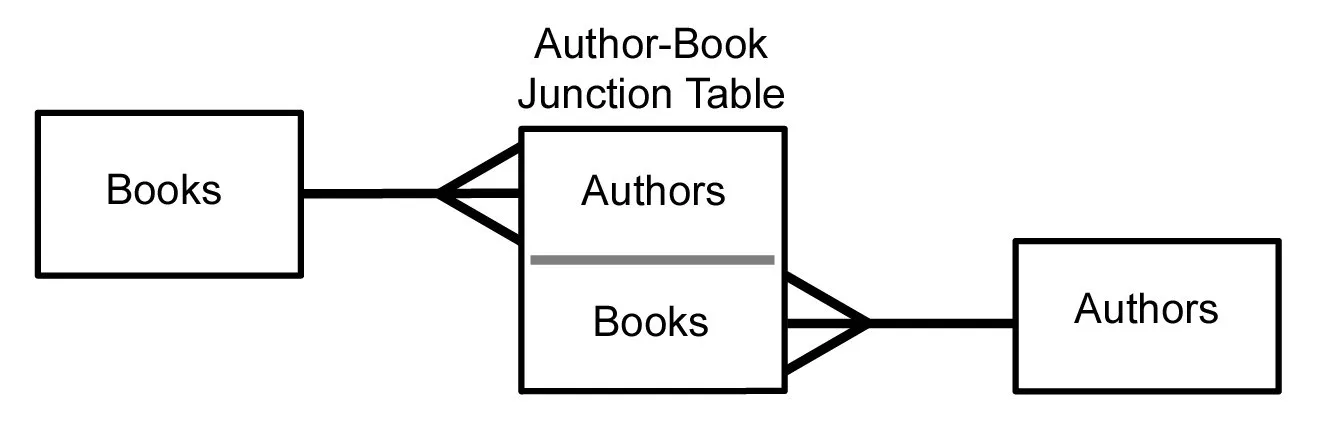
The third table connects the two tables and helps the relational database function smoothly.
Example: the first table contains students and their names, while the second table contains their courses. One student can attend many different courses. One course can have many different students.
Why this structure does not work for analytics use cases
If you want to create an embedded analytics dashboard, using database relationships is not such a good idea.
When data is normalized, it’s spread across different tables, which ensures consistent definitions. For business users, this means that they’ll often have trouble understanding or using all of this data. There are just too many options to choose from.
The second problem is that there is a vast number of unpredictable options to analyze. This means that your database optimizers won’t be able to keep up with query complexity. The end result? Your analytics dashboards will take ages to load for your end users.
For an analytics use case, a better option is something called a star schema. This involves one large “fact” database with e.g. orders. This table has relationships with several “dimension” tables, e.g. shops, products, customers, and others.
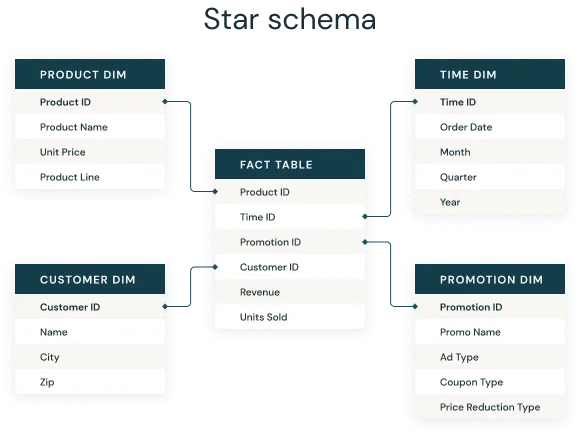
On top of that, we typically recommend customers to further denormalize their database structure into a single dataset.
This ensures your dashboards load quickly and that your end-users know what data they have and what they can do with it. If you want to learn how to create a great structure for an analytics use case, this is a good resource to get started.
Database relationships in practice: real-world schema examples
Database relationship types are easier to understand with concrete examples than abstract definitions. Here are three schemas that map directly to common software products.
E-commerce
A typical e-commerce database has a customers table and an orders table connected by a one-to-many relationship — one customer can place many orders, but each order belongs to a single customer. Orders and products are connected through a many-to-many relationship: a single order can contain multiple products, and any product can appear in multiple orders. This is usually handled with an order_items junction table that holds the order ID, product ID, and quantity.
software subscription product
A software product typically has a companies table linked to a users table in a one-to-many relationship: one company can have many users, each user belongs to one company. Subscriptions often sit on the company record in a one-to-one relationship — one active subscription per company at any given time. Usage events are connected to users in a one-to-many relationship and are usually the highest-volume table in the database.
HR platform
An HR platform connects employees to departments in a many-to-one relationship — many employees belong to one department. Employees and skills often have a many-to-many relationship through an employee_skills table, since any employee can have multiple skills and any skill can be held by multiple employees. Performance reviews connect to employees in a one-to-many relationship, with each review timestamped and attributed to a reviewer.
Database relationships vs. flat tables: what this means for analytics
The relational database structure described in this article — normalized tables connected by primary and foreign keys — is the right design for production applications. It minimizes redundancy, enforces data integrity, and scales well as data volumes grow.
For analytics, however, normalized data creates a challenge. Answering a business question like "What is the average revenue per customer segment this quarter?" typically requires joining four or five tables. Every join is an opportunity for errors, performance issues, and complexity that slows down query speed and makes it harder for non-technical users to access data directly.
This is why analytics pipelines commonly transform relational data into denormalized structures — wide tables or data models that pre-join the relationships most commonly needed for reporting. The transformation step, handled by tools like dbt or similar, creates an analytics-friendly version of the data without changing the production database.
For embedded analytics specifically, the data model you expose to end users matters as much as the underlying schema. Luzmo AI allows product teams to define a semantic layer on top of their data — mapping database relationships into human-readable concepts like 'customer', 'revenue', and 'period' — so that end users can query data in plain language without needing to know how the tables are joined.
Common errors in database relationship design
Database relationship errors range from beginner mistakes to architectural decisions that seem fine early and become expensive later.
Missing foreign key constraints is one of the most common. Without a foreign key constraint, it's possible to insert a record in the orders table that references a customer ID that doesn't exist in the customers table. The database won't stop it, and the error will surface later — often in an analytics query or a report that suddenly shows orphaned records.
Circular references occur when table A has a foreign key to table B, and table B has a foreign key back to table A. This isn't always wrong, but it creates problems for deletion (you can't delete either record without violating the other's constraint) and makes the schema harder to reason about.
Using many-to-many relationships without a junction table is a structural mistake that's hard to fix after data starts accumulating. If you try to store multiple product IDs in a single orders column as a comma-separated string, you lose the ability to query on individual values efficiently and can't enforce referential integrity.
Over-normalization is the flip side of the more commonly discussed under-normalization. Breaking data into too many small tables can cause performance issues in write-heavy workloads and make queries unnecessarily complex. The right level of normalization depends on whether the database is primarily read-heavy (analytics) or write-heavy (transactional).
Database relationships and analytics: what to know before building dashboards
Understanding your database relationships is a prerequisite for building reliable analytics. The way your tables are connected determines what questions you can answer, how quickly you can answer them, and what transformations are needed before data is ready to visualize.
The most common issue teams run into is querying on a join that produces duplicate rows. If you join orders to order_items without accounting for the fact that each order has multiple items, your revenue aggregations will overcount. Filtering, grouping, and aggregating correctly across joined tables requires knowing the cardinality of every relationship you're traversing.
A second consideration is query performance. Joins across large tables — especially many-to-many joins through junction tables — can be slow if the tables aren't indexed correctly. For embedded analytics where end users expect near-instant results, slow queries degrade the experience enough that users stop engaging with the dashboard.
This is why most embedded analytics implementations add a data modeling layer between the production database and the visualization. Luzmo AI connects to your data source, allows you to define the relationships and metrics that matter for your users, and handles the query optimization underneath — so product teams can focus on the analytics experience rather than the database plumbing.
Wrapping up
Luzmo pricing is designed to scale with your product as it grows. Plans start at €495/month for Starter, giving you everything you need to launch customer-facing dashboards quickly. The Premium plan, starting at €1995/month, adds advanced analytics, full white-labeling, and AI-powered insights for growing SaaS platforms. For larger deployments, Enterprise plans offer custom pricing, with dedicated infrastructure, enhanced security, and flexible scaling.
All plans are built around your usage, so you can start small and expand your analytics experience without reworking your stack.
Book a free demo today so we can tell you more!
FAQ
All your questions answered.
What are the fundamental types of database relationships?
1. What are the fundamental types of database relationships? In relational databases, there are three types of core relationships. One-to-One is a single record in one table connects to one record in another. One-to-Many is when a single record links to many records in another table (e.g., one customer with many orders). Many-to-Many is when many records link to many others via a join table. These structures organize data logically and make querying efficient.
How do relationships affect query performance?
Efficiently defined relationships (with proper foreign keys and indexing) allow databases to join tables quickly. Poorly constructed relationships - or missing indexes - can result in slow joins and long query times, especially when data volumes are high. Design matters for performance at scale.
How do I choose between normalization and denormalization?
Normalization (breaking data into related tables) minimizes redundancy but can make queries complex. Denormalization (combining tables) can speed up analytics at the cost of redundancy. Analytical systems often lean toward denormalized schemas or star/snowflake models to optimize reporting speed.
How do relationships differ in SQL vs NoSQL systems?
SQL databases model relationships explicitly with keys and joins. NoSQL systems (document stores, key-value stores) handle relationships more flexibly or implicitly - either through embedded documents or application layer logic. Choosing between them depends on access patterns and scalability needs.
Written by

Ship the future of your data
Let us show you what Luzmo can do for your product.

Leave your e-mail and one of our analytics experts will reach out to you