Redshift vs BigQuery: Cloud Data Warehouse Comparison [2026]
![Redshift vs BigQuery: Cloud Data Warehouse Comparison [2026]](/assets/migrated/dee8ff8d1c53f49e.webp)
Your SaaS product generates a mountain of data: usage metrics, customer behaviour, campaign performance.
And inside that data lie actionable insights for your users. Imagine a recruitment platform that shows HR managers exactly where applicants are dropping off, or a marketing dashboard that surfaces your clients’ best-performing campaigns at a glance.
But before you can build interactive, lightning-fast dashboards, you need the right data infrastructure.
The data warehouse you pick will influence your ability to connect to your data, explore raw metrics, visualize data, and create a true data-driven product.
In this comparison of Amazon Redshift vs Google BigQuery, we’ll help you decide which cloud data warehouse fits best, especially if you aim to embed analytics in your SaaS platform and empower your users to analyze and use data effectively.
What is Amazon Redshift?
Amazon Redshift is a fully managed, petabyte-scale cloud data warehouse service from Amazon Web Services (AWS). It enables you to store large volumes of data, whether that’s SaaS product usage metrics, customer events, transactions or log data, and run high-performance queries and business intelligence workloads.
Here are some of its key capabilities:
Fully managed: It handles provisioning, patching, backups and scaling for you.
Flexible architecture: You can choose between provisioned clusters and the newer serverless model (Redshift Serverless) where infrastructure is largely abstracted away.
SQL-based analytics: Redshift supports familiar SQL syntax and integrates with popular BI and data visualization tools, making it friendly for teams that already know SQL.
High scale & performance: With columnar storage, massively parallel processing (MPP), and the ability to query data lakes, it’s built for large analytic workloads.
Strong integration in AWS ecosystem: Easily combines with Amazon S3, Amazon Kinesis, Athena, and other AWS services.
Why it matters for SaaS companies
If your SaaS product is generating lots of data about user behaviour, feature usage, conversion funnels or campaign performance, Redshift offers a warehouse where you can connect to your data, model metrics across rows and columns, and power embedded dashboards or internal analytics features with confidence. Teams of data engineers, analysts and data scientists often pick Redshift for workloads where they want tight control over performance, concurrency and scaling.
Things new in 2026 to keep in mind
Redshift now emphasizes “zero-ETL integrations” so you can bring streaming operational data into your warehouse with less overhead.
Security defaults have been improved: new clusters now disable public access by default, enforce encryption at rest and in transit, and require SSL connections by default.
A key upcoming change: After November 1 2025, Redshift will no longer allow new Python UDFs on clusters.
What is Google BigQuery?
Google BigQuery is a fully-managed, serverless cloud data warehouse offered by Google Cloud. It’s designed for modern data-driven analytics, enabling you to connect to your data, visualize data, and perform data analysis and business intelligence at scale, without the burden of managing infrastructure.
Here’s what you get with BigQuery:
Serverless architecture: you don’t need to manage clusters, nodes or capacity; BigQuery handles the scaling for you automatically.
Separation of storage and compute: storage and processing are decoupled, so you can scale each independently and avoid paying for compute you’re not using.
Support for large volumes of data and interactive queries: it’s built to let analysts, data scientists and business intelligence teams explore data, build dashboards and surface insights fast.
Rich integrations: BigQuery works well with other Google Cloud services, streaming ingestion, and supports standard SQL and familiar BI workflows, making it friendly for teams that already use data and use data visualization tools.
Why this matters for SaaS companies
If your SaaS product is generating usage metrics, feature-engagement data, marketing performance or customer events, BigQuery offers a strong foundation to connect to your data, let your team explore data, and embed analytics features that let customers visualize data and act on it. Because it's serverless, you can scale quickly and focus fewer resources on infrastructure and more on building value.
Things to keep in mind in 2026
While BigQuery removes much of the infrastructure burden, you still need to think through data ingestion, schema design, cost management and query optimization (especially if you aim for many embedded users querying your warehouse frequently).
If you have predictable heavy workloads or very deep tuning needs (e.g., fine-grained control over resource allocation, custom sort/distribution keys) then the trade-off of less infrastructure control might matter.
BigQuery vs Redshift - Architecture
When you're deciding choosing the right data warehouse, you’re really comparing architecture, control, cost and how well the platform handles your data volumes and use cases. In this Redshift vs Google BigQuery cloud-based data warehouse comparison, let’s outline how these two differ, and where each shines (especially vs Snowflake in broader comparison).
Serverless vs Cluster-based
In the comparison of Google BigQuery and Amazon Redshift, one of the first big distinctions is how they handle computing and storage:
BigQuery features a serverless architecture: you don’t size clusters, you don’t worry about scaling nodes. It automatically handles growth in data volumes and spikes in queries.
Redshift offers a cluster-based model (although newer Redshift Serverless options are appearing): you choose node types, set up clusters, scale them manually or semi-automatically. Redshift requires more hands-on management.
Because of this, if you expect highly variable workloads and need agility, BigQuery often wins in this category. But if you have predictable workloads and want more control, Redshift may be a better fit.
Storage & compute separation
Another fundamental difference: how storage and compute are combined or separated.
BigQuery decouples storage and compute: you pay for storage and queries independently, giving flexibility for varying workloads.
Redshift traditionally couples storage and compute within nodes, giving you tighter control but possibly less flexibility when you have fluctuating demand.
For SaaS platforms dealing with peaks and troughs (e.g., many customers using dashboards concurrently), decoupled storage/compute can be a big plus.
Structured & semi-structured data, data Integration & streams
In the broader cloud data warehouse comparison (including vs Snowflake), one must look at how each handles structured and semi-structured data, streaming data, data pipelines, and data integration.
Redshift offers strong support for structured data, and with features like Spectrum and integrations to S3, it also handles semi-structured formats, but often with more setup required.
BigQuery excels in semi-structured formats (e.g., JSON, nested fields) and is built for high-scale data streams, letting analytics and data exploration happen quickly across huge volumes.
Regarding integration: Redshift offers deep AWS-ecosystem support (S3, Kinesis, Lambda) for streaming data and heavy ETL pipelines. BigQuery integrates tightly with GCP but some specific streaming/ingestion use cases may require different tooling. As analyses show, if you need heavy data integration and long-established data pipelines, Redshift might be more mature.
When you have massive data volumes & BI workloads
Because your SaaS product generates lots of usage, event, and customer data, the data volumes and query patterns matter.
If you’re dealing with many concurrent users, large dashboards, high concurrency and you already have an AWS ecosystem, Redshift often delivers strong performance when tuned correctly.
If you’re dealing with extremely large ad-hoc queries, many users querying varied datasets, or you need rapid elastic scaling, BigQuery may give you more flexibility out of the box.
Versus Snowflake context
In many end-user analyses of Snowflake vs Redshift vs BigQuery, you’ll see that Snowflake sits between these two by offering cloud-native separation of compute/storage, strong data sharing, and multi-cloud flexibility. In the Redshift vs Google BigQuery comparison, this third option often nudges decision-memories but if you’re focused purely on AWS or GCP, you’ll pick between Redshift and BigQuery.
Embed your first dashboard in less than 10 days.
TRY LUZMO FREE
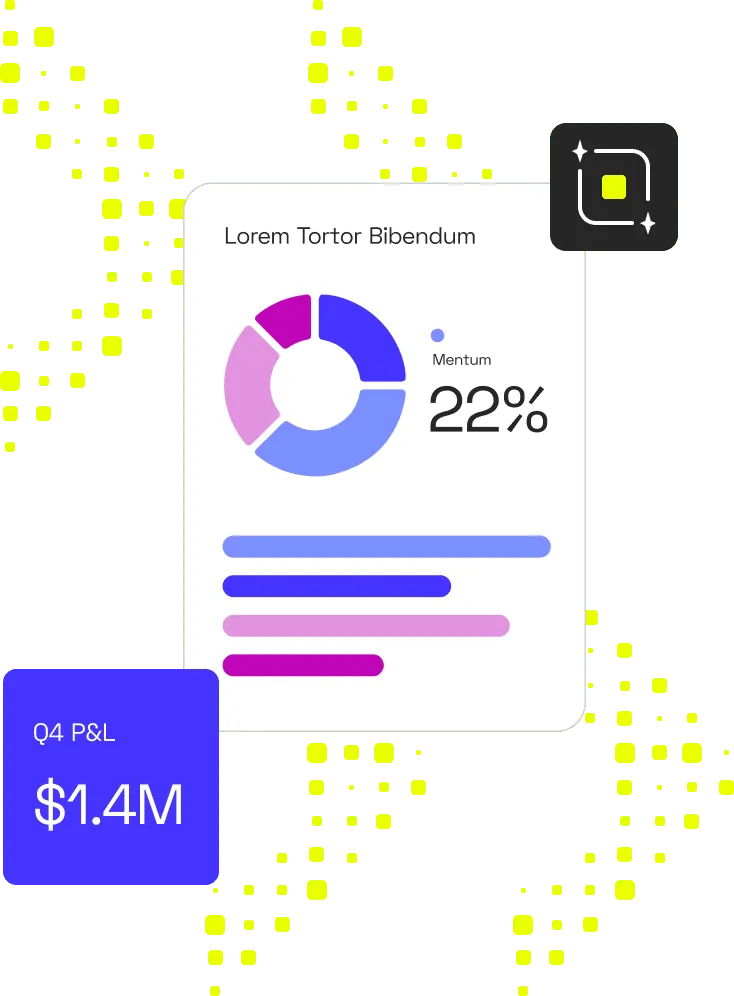
BigQuery and Redshift - performance
Both Google BigQuery and Amazon Redshift are quite fast and efficient when it comes to data storage, large-scale loading and running queries. But they handle performance in different ways, and if you’re deciding between BigQuery vs Redshift for your SaaS’s embedded analytics, the differences matter a lot.
Query execution and scalability
Both platforms can deal with high data volumes, but their architectures diverge. BigQuery’s serverless model means you don’t have to pre-allocate infrastructure or worry about the size of your cluster ahead of time. BigQuery uses Google’s Dremel-based engine to execute queries across massive datasets very quickly.
If speed is essential and you don’t want to manage infrastructure, use BigQuery is a strong recommendation.
Redshift, in contrast, uses a more traditional Massively Parallel Processing (MPP) model with clusters of nodes working in parallel. It adds features like concurrency scaling to handle bigger workloads. If your query patterns are complex (many large joins, or complex dashboards), Redshift often caters better to that. It gives more control but demands more management.
Performance optimization
When it comes to tuning your warehouse for best performance:
With BigQuery, much of the optimisation is automatic, so you don’t need to worry about distribution keys, sort keys, or vacuuming.
Redshift, however, requires more manual tuning: choose distribution keys (which data resides on which node), sort keys (how data is arranged in table), vacuuming or re-organising data as inserts/deletes happen.
This again underlines the trade-off: BigQuery is excellent for business intelligence teams wanting fast setup and minimal infrastructure work, while Redshift offers more flexibility and control when you’re willing to manage it.
Real-world implications for SaaS analytics
When you’re choosing the right data warehouse for your product’s analytics, whether you build internal BI features or user-facing dashboards, here’s how this performance difference plays out:
If you anticipate a wide variety of ad-hoc queries, many users exploring data, or unpredictable usage patterns, BigQuery’s serverless architecture gives you elasticity and ease of scaling.
If your workload is steady, predictable, many users always running the same dashboards or reports, and you already live in the AWS ecosystem, then Redshift offers predictable performance and cost when you tune it well.
Also note: if you’re aiming for data integration with lots of streaming ingestion, real-time data pipelines, or combining structured and semi-structured data, the performance tuning demands will rise. Redshift may demand more engineering effort; BigQuery eases overhead but you still need to watch costs and query efficiency.
In short: BigQuery doesn’t force you to manage infrastructure and scale nodes manually, making it a strong choice for many modern SaaS use cases. But if you want deep control over performance, cost and workload patterns, Redshift remains a top choice.
Redshift vs BigQuery - data types and integration
Both Google BigQuery and Amazon Redshift are well suited for structured data with defined schemas, but they each handle more complex formats and data integration in distinct ways. If you’re choosing a cloud-based data warehouse for your SaaS product, understanding how they deal with semi-structured formats, data stores, data pipelines and query performance is key.
Handling structured & semi-structured data
BigQuery excels when your data set includes nested JSON, arrays or other semi-structured formats - you can load data and run queries without much manual schema work.
Redshift also supports semi-structured formats (e.g., JSON, Avro) via external tables or its Redshift Spectrum feature. With Spectrum you can query data stored in Amazon S3 (a common data store) rather than loading everything into the cluster.
If you manage large data volumes of logs, event streams or nested records, BigQuery’s architecture tends to require less upfront schema design and gives more flexibility.
Integration & pipelines
Redshift provides deep integration with the AWS ecosystem (including S3, Athena, Kinesis and Lambda) which helps when you have streaming data, data streams or complex ETL-style data pipelines.
BigQuery integrates tightly within the Google Cloud Platform stack (Cloud Storage, Pub/Sub, Dataflow) so if you already leverage GCP services it simplifies your workflow. However, if you require highly custom or cross-cloud ETL flows, BigQuery doesn’t always offer as much fine-grained control as Redshift.
Both warehouses enable you to use standard SQL, connect BI tools and visualize data on top of your analytics layer - an important part of building downstream dashboards and embedded analytics.
Choosing the right data warehouse for your use case
When you’re choosing the right data warehouse, ask how your platform uses data sets:
If you expect lots of nested or semi-structured fields, frequent schema changes, streaming ingestion and dynamic data stores - BigQuery is designed to simplify many of those workflows.
If you deal mostly with large, well-structured tables, predictable query patterns, heavy ETL pipelines and existing AWS infrastructure, then Redshift offers more control, supports advanced tuning and has mature integration paths.
If your dashboard-driven analytics rely on both high query performance and smooth integration of multiple data streams and stores, then the decision between Redshift vs BigQuery comes down to your team’s skills, your data architecture and ecosystem alignment.
Google BigQuery vs AWS Redshift - pricing model
Although price alone shouldn’t determine your choice of a cloud-based data warehouse, it’s definitely worth considering when comparing options.
Google BigQuery pricing
On the Google BigQuery side (on the Google Cloud platform), you typically use BigQuery in a pay-as-you-go model where you are charged based on the amount of data processed in queries and for storage of data stored.
This model is ideal for workloads that vary a lot: for example, a SaaS product managing events or seasonal campaigns where summer months see high traffic and winter months are light. Since you’re billed for the data scanned or slot usage, you avoid having to size clusters upfront.
AWS Redshift pricing
On the Amazon Redshift side (on the Amazon Web Services platform), you pay primarily for the capacity of your cluster or for the compute/storage you’ve provisioned, which may make it more predictable if your workload is steady.
If you have predictable usage and many consistent queries, Redshift may turn out to be cheaper than being charged per query. Once you stay within your node’s limits and tune your cluster, many queries are effectively free within the capacity you’ve paid for.
Comparison & caveats
While BigQuery pricing is more flexible and adapts well to variable data volumes, Redshift’s flat-rate or node-based pricing is more predictable upfront.
BigQuery’s default on-demand pricing model bills by bytes processed or slot hours, which means if you run many large queries, billing can grow quickly. Redshift requires more manual management (clusters, scaling) but gives more control.
Both pricing regimes have advantages and disadvantages depending on your use case: variable vs predictable workload, GCP vs AWS ecosystem, queries vs storage vs compute.
Which cloud data warehouse is right for your use case?
Amazon Redshift and Google BigQuery are both solid providers for SaaS companies that are building analytics features. If you want to offer engaging charts and dashboards to your product users, both are capable of fast‐loading, smooth experiences. But which one is better depends on your specific use case.
Google BigQuery stands out for its ease of use: scaling petabytes of data becomes effortless, thanks to its many automations. If you anticipate many ad-hoc queries, variable workloads, or you want fast, on-demand analytics without managing infrastructure, BigQuery is likely the best choice for you.
Amazon Redshift is the master-tool when your priorities are controlling data processing, performance tuning and predictable scaling. If you have a steady heavy volume of queries, a strong AWS ecosystem, and you want advanced control over your cluster architecture, then Redshift might be the smarter pick.
Now that you understand which data warehouse might be right for you, it’s time to turn your cloud-stored data into interactive dashboards and meaningful insights. If you’re looking for a visualization and analytics layer that fits seamlessly into your SaaS product, consider the capabilities of Luzmo. With out-of-the-box connectors to BigQuery and Redshift, you can start building dashboards for your product users in days, not months.
Here is how Luzmo supports you:
Luzmo Studio: a drag-and-drop dashboard builder for fast visualisation and deployment into your product.
Luzmo Flex: a code-first SDK that gives your engineering team full control over embedding and custom analytics experiences.
Luzmo IQ: add AI-powered insights, natural-language querying and automatically surfaced trends for end users.
Agent APIs: trigger in-app actions, embed analytic workflows, and integrate your dashboards with user behaviour and your product UI.
If you’re ready to accelerate your analytics delivery, our team of analytics experts will gladly show you a demo and guide you on choosing the right data infrastructure. Book a free consultation today.
Written by

Ship the future of your data
Let us show you what Luzmo can do for your product.

Leave your e-mail and one of our analytics experts will reach out to you