Snowflake vs Redshift: Best Data Warehouse for SaaS

Choosing the right data warehouse for your SaaS business can be a complex task. Whether you're analyzing big data, performing data management, or building data pipelines, a cloud-based data warehouse is crucial for efficiency.
In this comparison, we’ll explore the key differences between Snowflake and Amazon Redshift, two leading data warehousing solutions. We’ll break down their pricing models, compute resources, scalability, and performance optimization to help you choose the best fit for your business needs.
What is Snowflake?
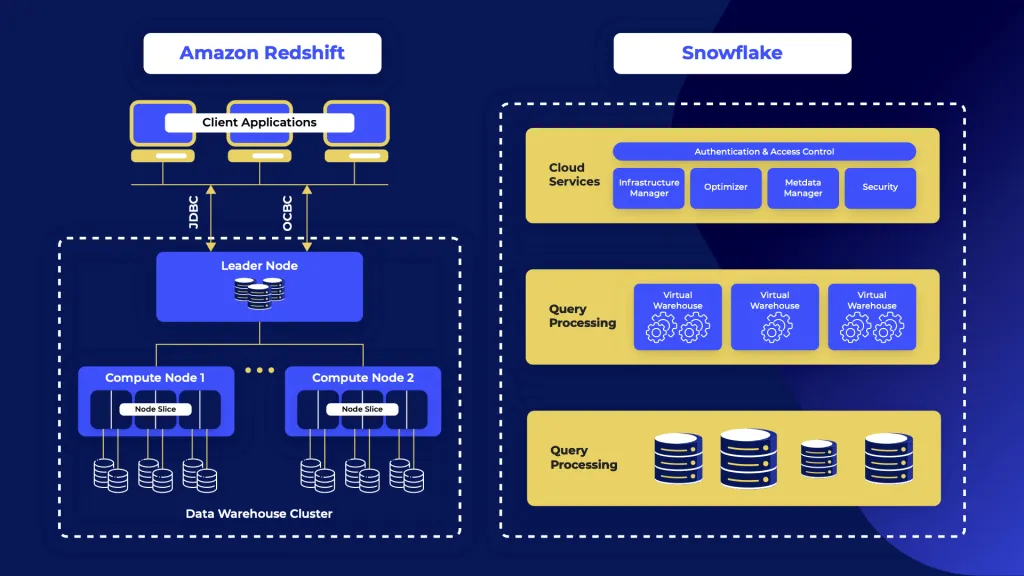
Snowflake is a powerful, cloud-agnostic data warehouse that operates on AWS, Google Cloud (GCP), and Azure. It’s popular for handling structured and semi-structured data like JSON and Avro, making it highly versatile for a range of data types.
Snowflake’s architecture is built around virtual warehouses, allowing automatic scaling of compute resources to handle high concurrency workloads without impacting query performance. This is ideal for SaaS companies that need flexibility in handling large datasets while keeping costs manageable with an on-demand pricing model.
Snowflake supports real-time data analytics and business intelligence applications with little manual provisioning, making it a user-friendly option for businesses that need data-driven insights without heavy technical overhead.
What is Amazon Redshift?
Amazon Redshift is a PaaS (Platform as a Service) solution provided by Amazon Web Services (AWS). It’s designed for data engineering and data analytics and is a popular choice for AWS Redshift users because of its tight integration with AWS services like Amazon S3, EMR, and VPC.
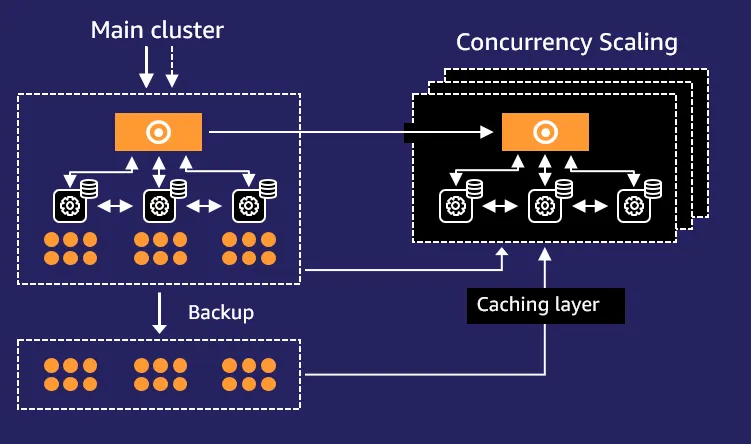
Redshift’s architecture relies on clusters, where each Redshift cluster consists of a leader node and multiple compute nodes. This structure uses Massively Parallel Processing (MPP) to handle large datasets with efficient data storage and concurrency scaling.
For businesses already deeply invested in the AWS ecosystem, Redshift offers seamless integration with other cloud services, making it an ideal choice for those looking for tighter control over compute resources, data management, and scalability.
Key similarities between Snowflake and Redshift
Columnar storage
Both Snowflake and Amazon Redshift utilize columnar storage for faster, more efficient querying. This structure is optimized for analytical workloads and speeds up performance for large datasets.
Concurrency scaling
Both solutions support concurrency scaling, allowing multiple queries to run simultaneously without slowing down performance, making them suitable for real-time analytics and data platforms.
Semi-structured data
Snowflake and Redshift can handle semi-structured data like JSON, Avro, and Parquet. However, Snowflake supports these formats natively, while Redshift Spectrum must be used to query semi-structured data stored in Amazon S3.
Key differences between Snowflake and Redshift
1. Architecture and compute resources
- Snowflake separates compute from data storage with its virtual warehouse architecture, allowing auto-scaling without the need for manual intervention. This is ideal for companies with unpredictable workloads who need automatic scaling for both big data and small tasks.
- Amazon Redshift, on the other hand, uses a cluster-based architecture, where compute nodes and leader nodes require manual tuning for performance. This offers more control but requires more hands-on optimization, such as setting distribution keys and performing vacuuming to optimize data.
2. Data integration and ecosystem
- Snowflake is cloud-agnostic, which means it can run on multiple cloud platforms like AWS, Azure, and Google Cloud (GCP). This makes it a great fit for businesses with multi-cloud strategies.
- Amazon Redshift is tightly integrated with AWS services, making it the better choice for businesses already operating within the AWS ecosystem. Its native integrations with tools like EMR, VPC, and S3 enhance its ability to manage large-scale data pipelines.
3. Pricing models
- Snowflake offers an on-demand pricing model that charges based on the amount of time it takes to process a query. This is particularly cost-effective for businesses with variable query workloads.
- Redshift uses a reserved instance pricing model, which allows for more predictable costs, making it a great option for businesses with consistent query loads. If your data workloads are steady, Redshift's flat-rate pricing could offer a better deal.
4. Performance optimization
- Snowflake automates query optimization using micro-partitioning, which breaks down large data into manageable parts for faster data analysis.
- Amazon Redshift provides more manual control over query performance but requires fine-tuning to optimize large data warehouses. You may need to set compute nodes manually to handle petabyte-scale data.
5. Security features and access control
- Snowflake uses a built-in role-based access control (RBAC) system, which is user-friendly and works across multi-cloud environments.
- Amazon Redshift leverages AWS Identity and Access Management (IAM) for authentication and access control, which is particularly beneficial for businesses already using other AWS services.
Which data warehouse solution is right for you?
When deciding between Snowflake and Redshift, it’s important to consider your specific use cases and existing infrastructure.
Choose Snowflake if you need:
- Automated scalability and auto-scaling for unpredictable workloads.
- A cloud-agnostic solution that works on AWS, Azure, and Google Cloud.
- Easy handling of semi-structured data without the need for external tools.
Choose Amazon Redshift if you need:
- Tight integration with AWS services for seamless data management.
- Predictable reserved instance pricing with full control over compute resources.
- A solution for handling petabyte-scale data within the AWS ecosystem.
SQL and ETL in Redshift vs. Snowflake
When it comes to handling SQL queries and managing ETL (Extract, Transform, Load) processes, Redshift and Snowflake offer distinct advantages for modern data applications.
Redshift relies on its strong integration with PostgreSQL, making it a familiar option for users who need a relational database setup. Redshift excels when you need to perform heavy ETL tasks or use machine learning models, especially when leveraging AWS’s data lake and metadata management capabilities. Caching in Redshift can also improve query performance, particularly with consistent workloads.
On the other hand, Snowflake simplifies SQL and ETL processes with built-in automation features.
It’s especially suited for teams that need seamless data sharing across cloud providers like Google BigQuery or Azure. Snowflake separates compute and storage, allowing greater flexibility when scaling up or down for complex data pipelines.
Whether you use Redshift or Snowflake, both offer efficient ways to manage modern data and optimize SQL workloads, but the choice will depend on your integration needs and preferred cloud provider.
Snowflake vs Redshift pricing: Which cloud data warehouse fits your strategy?
When evaluating Snowflake vs Redshift pricing, it’s essential to consider how each cloud data warehouse supports your overall data strategy. Both platforms offer robust tools for storing and processing semi-structured data types, though their approaches to costs and features differ.
Snowflake excels with its virtual data warehouse model, which allows for flexibility and scalability. It also supports multiple data output formats, enabling diverse use cases. Redshift, on the other hand, integrates seamlessly with database migration services and offers features like cluster security groups to enhance security.
In terms of data protection, Snowflake provides strong data encryption, while Redshift uses load data encryption alongside cluster encryption for additional safeguards. Both platforms also prioritize efficiency, with Snowflake emphasizing innovative data compression techniques and Redshift offering cost-effective options for those needing to store data in high volumes.
Ultimately, the decision between these cloud data warehouses hinges on your need for performance, security, and cost alignment with your specific use case. Both offer competitive pricing models tailored to different business requirements.
Conclusion
Both Snowflake and Amazon Redshift offer powerful, scalable data warehousing solutions for SaaS companies. If you’re looking for automated, flexible scaling, Snowflake is your best option. For businesses operating in the AWS ecosystem with more predictable workloads, Redshift provides more control and tighter integration.
Once you’ve selected your data warehouse, it’s time to visualize your data.
Luzmo integrates seamlessly with both Snowflake and Redshift, enabling you to create dashboards and perform real-time analytics quickly. Our pricing is transparent and built for SaaS scalability, starting at $495/month for Starter and $1,995/month for Premium, with Enterprise plans available as you grow.
Book a free consultation today and get started building your interactive dashboards in days, not months.
Written by

Ship the future of your data
Let us show you what Luzmo can do for your product.

Leave your e-mail and one of our analytics experts will reach out to you