What is Data Standardization? Examples and Use Cases

Handling data analytics with data in different formats would be like trying to bake a cake by throwing in an unopened carton of milk. Sure, you’d technically follow the recipe, but the result won’t be cake-like.
Without data standardization, there is no coherent data analysis, visualization, data transformation, or reliable insights. Let us show you what this process is and how it works.
What is data standardization?
Data standardization is the process of transforming data from various sources into one common format so that all data in a dataset has the same structure and meaning.
For example, you need to analyze the impact of daily commutes on the job satisfaction of employees. Some drivers report they drive 50 kilometers while others drive 31 miles. While the length is essentially the same, a data analytics tool only reads the numbers and registers them as two different values. As a consequence of these different data formats, the end result can be invalid.
Data standardization ensures all data points are in the same format, so you’re not arriving at the wrong conclusions or comparing apples to oranges In other words, it’s metadata - data about data.
Data standardization includes processes such as:
- Converting units (e.g. transferring all data values from miles to kilometers)
- Normalizing formats (e.g. standardizing date formats, metrics, or currencies, removing redundancy)
- Ensuring consistency in data type (e.g. maintaining consistent capitalization and naming conventions in one standard format)
There are multiple benefits of data standardization:
- It ensures high data quality
- It makes comparability easier, as you’re comparing the same categories and there are no discrepancies
- It makes data integration and interoperability easier
- It improves efficiency for later use in advanced analytics, machine learning, and automation
- It supports compliance and data governance
- It optimizes decision-making for all stakeholders
Data standardization vs. data normalization
The two terms are commonly used together but have completely different meanings and use cases.

Data normalization is a technique for scaling numerical data into a specific range, usually between 0 and 1, without changing the relationships between the values. It’s particularly useful when different features in a dataset have varying units or scales so that no single feature dominates an analysis because of its range.
These are some of the most common situations when you’d need data normalization:
- When your data has outliers and does not follow a Gaussian distribution
- When using machine learning algorithms like neural networks and k-nearest neighbors (KNN) that are sensitive to data range
- When you want to bring different features in the same scale without assuming a particular distribution
What happens when you don’t standardize data?
When your datasets are not standardized, this can lead to a number of issues for everyone in the data management and analysis process.
- Inconsistent data interpretation. For example, different formats or units (dates, measurements, currencies) could lead to the wrong conclusions. Having your data in mm/dd/yyyy vs dd/mm/yyyy format could lead to problems during the analysis process.
- Data integration problems. When data comes from different sources and it’s not standardized, it becomes hard to integrate it, and e.g., visualize it in one tool.
- Errors in analysis and reporting. When data does not have a consistent format, your BI tool can fully omit it and return flawed analysis and wrong conclusions.
- Inefficient data processing. If all the data elements don’t have the same format, data processing workflows take more time.
- Poor performance of machine learning models. These models require consistent input to be able to produce reliable predictions.
- Compliance risks. In industries such as healthcare, where compliance with legislation is crucial, neglecting data standardization can be risky.
In short, when your data is not in a uniform format, your analyses may be inaccurate or unsuccessful.
Examples and use cases of data standardization
Data standardization is easier to understand through practical examples. Here are a few to highlight why this practice is extremely important for data analytics.
In climate science: data points such as temperature, humidity, precipitations, and others often have different units or scales. Standardization rules make it easier for climate experts to compare data points across geographical locations after data entry.
In customer behavior analytics: let’s say you own a Software-as-a-Service product and collect various types of data related to customer retention using the Pendo digital adoption platform. Time spent using the app, engagement rates, churn rates, and other metrics are highly valuable data. However, each metric will have different scales – and to be able to use them for analysis, they need to be standardized.
In medical research: each medical research collects a variety of data points, such as cholesterol levels, blood pressure, heart rate, and many others. All of these items have different ranges and units and comparing them would be impossible – unless the data is standardized first.
In financial and stock market analysis: when you’re comparing stock returns across different companies with varying scales of values, standardization is necessary. For example, one company’s stock value could range from $100 to $200, while another may go from $10 to $50. Standardization removes the impact of differences in price ranges so that in an analysis, it’s easier to see trends and patterns.
How does data standardization work? Step-by-step guide
Data standardization is typically done using programming languages such as Python and R or even an app such as Excel.
- Collect and understand your data
Gather the data from various data sources – and before standardization, make sure it’s clean. This data cleansing process means removing missing values, outliers, and irrelevant features. Identify the numerical columns in your dataset that need to be standardized.
- Calculate the mean and standard deviation
For each numerical feature (column), calculate standard deviation and the mean.
Mean (μ): The average value of the data in the feature.
Standard deviation (σ): A measure of how spread out the values are from the mean.
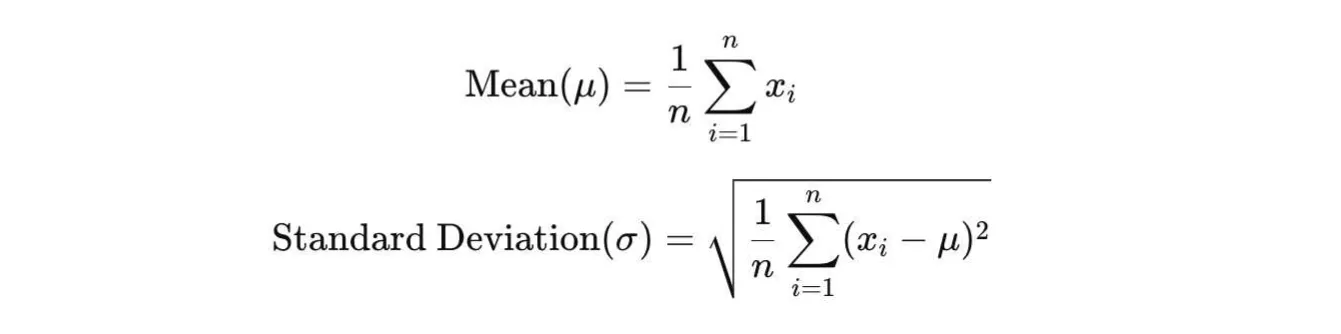
- Apply a standardization formula
The standardization formula should be applied to each data point.
Once the standardization is complete, you’ll have a list of features with a mean of 0 and a standard deviation of 1.
- Repeat for all numerical features
Repeat the process above for all the numerical features that need to be standardized.
- Verify the results
Once the standardization is done, you should verify that the mean of the standardized feature is 0 and the standard deviation is close to 1. You can do this in e.g., your programming tool using the statistical summary functions.
- Use the standardized data for further analysis
The final master data set can now be used for analysis (e.g., prescriptive analytics), visualization, or anything that requires scaled and standardized data.
Conclusion
Great data quality is the basis for accurate data analysis. It facilitates better decision-making,and more valuable insights and allows you to get the maximum value from your data sources.
And once you’ve finished the data standardization process, the best way to understand the meaning behind the numbers is to visualize said data. At Luzmo, we can help you do that and visualize insights for the end-users of your app.
Platforms like Luzmo Studio make it easy to turn standardized datasets into interactive dashboards and visualizations embedded directly in your product. With Luzmo IQ, teams can automatically surface trends, anomalies, and patterns in their standardized data, while Luzmo AI lets users ask questions in natural language and instantly generate insights from their dashboards.
Want to learn more? Book a free demo with our team and we’ll show you how.
FAQ
All your questions answered.
Why is data standardization important for data analysis?
Data standardization ensures that all data points follow the same format, units, and structure so they can be compared and analyzed reliably. Without standardization, inconsistencies in units, formats, or naming conventions can lead to incorrect conclusions, flawed reporting, and inefficient data processing.
What is the difference between data standardization and data normalization?
Data standardization converts data from different sources into a consistent format so datasets can be combined and analyzed accurately. Data normalization, on the other hand, scales numerical values into a specific range (often between 0 and 1) to ensure that no variable dominates an analysis due to its scale. Both techniques are important but serve different purposes in data preparation.
How can teams turn standardized data into insights?
Once data is standardized, it becomes much easier to analyze and visualize. Tools like Luzmo Studio allow teams to build dashboards and visualizations from standardized datasets, while Luzmo IQ can automatically surface trends and patterns across the data. With Luzmo AI, users can even ask questions about their data in natural language and receive instant insights, helping teams move from clean data to actionable decisions faster.
Written by

Ship the future of your data
Let us show you what Luzmo can do for your product.

Leave your e-mail and one of our analytics experts will reach out to you