Modern Data Stack: the Definitive Guide for Data Professionals

If you're like the average mid-to-large business, you likely handle large volumes of data from multiple sources. You'll need tools to make sense of this data and tie it to business outcomes. On the one hand, there’s the tried-and-tested legacy tool stack; on the other, there's a modern data stack that offers flexibility, scalability, and efficiency.
This article will demystify the modern data stack (MDS) and explore why it goes beyond the buzzword it's become in recent years.
What is a modern data stack?
A modern data stack (MDS) is a collection of tools that enables businesses to efficiently collect, store, transform, clean, and visualize data. Unlike legacy systems, which bundle everything in one rigid system, the MDS offers a composable approach.
With an MDS, businesses can choose different tools for each stage of the data management process, aligning their tech stack with specific business needs.
The history of the modern data stack
The modern data stack (MDS) emerged as a solution to the inefficiencies of traditional data management systems. In the past, businesses relied heavily on on-premise data infrastructure.
These legacy systems required significant hardware, software, and ongoing maintenance investments. As data volumes grew, so did the challenges. Scaling these systems meant adding more hardware, which was time-consuming and costly.
With the advent of cloud computing in the early 2000s, businesses realized the potential for more flexible and scalable solutions. Amazon Web Services (AWS) revolutionized data storage with services like S3 and EC2, allowing companies to store and process data in the cloud.
This shift marked the beginning of the modern data stack, where data tools became more modular and cloud-native.
Over the last decade, companies have moved from monolithic, legacy systems to modular architectures that allow them to choose the best tools for each task.
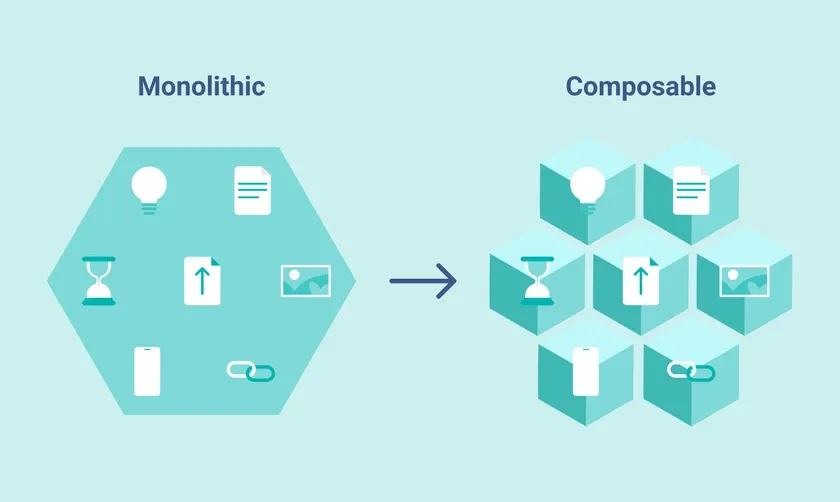
Today, the modern data stack includes ETL/ELT pipelines, cloud data warehouses, and data visualization tools that can scale with business needs. As businesses adopt AI and machine learning, the modern data stack continues evolving, incorporating new tools for handling unstructured data and real-time processing.
Modern data stack vs. legacy data stack
The difference between modern and legacy data stacks goes beyond technology—it reflects a fundamental shift in how businesses manage and process data.
Composable Architecture vs. Rigid Systems
In legacy systems, businesses rely on a bundled set of tools provided by a single vendor. These tools are tightly integrated, but this also means they are rigid. If a business wants to swap out or upgrade a tool, they often need to replace the entire system. This leads to high switching costs and vendor lock-in.
On the other hand, a modern data stack is composable, meaning businesses can choose the best tool for each step of the data lifecycle – data collection, storage, transformation, and data visualization. If a better tool becomes available, it can be integrated without overhauling the entire system.
Cloud-First vs. On-Premise
Legacy systems are predominantly on-premise, so companies must invest in infrastructure, maintenance, and upgrades as data grows. Scaling these systems is often expensive and requires more physical hardware.
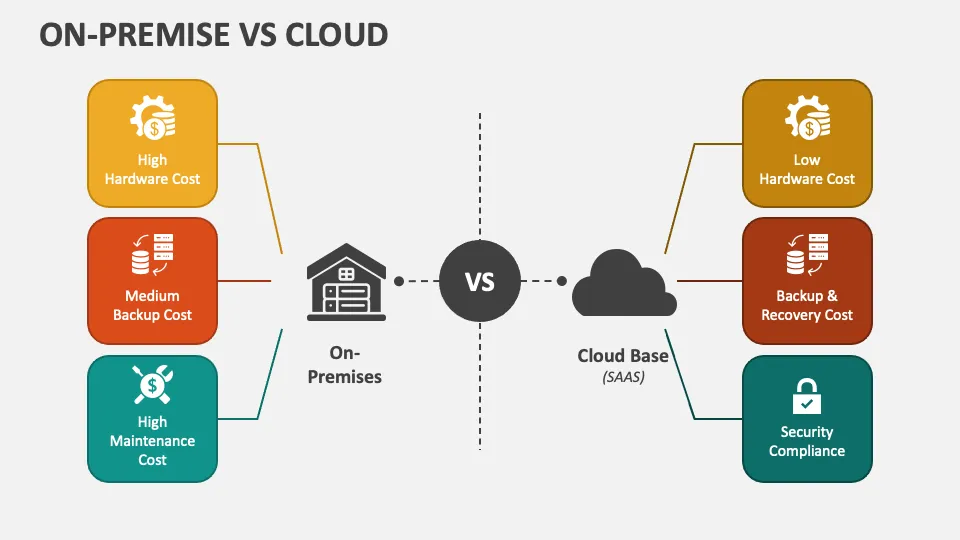
In contrast, modern data stacks are built for the cloud. Cloud-native solutions allow businesses to scale effortlessly. You only pay for the resources you use, and there's no need to worry about physical limitations.
Clickhouse is an increasingly popular cloud-based data warehouse known for its high-performance analytics capabilities, especially when handling big data.
Unlike traditional data warehouses like Snowflake or BigQuery, Clickhouse excels at real-time data analytics, allowing businesses to process and query massive datasets with minimal latency.
This makes it particularly valuable for use cases where speed and efficiency are critical, such as ad tech, finance, and e-commerce.
In addition to its speed, Clickhouse is highly scalable, supporting large enterprises and startups looking for cost-effective ways to manage their growing data needs. Its open-source nature allows for greater customization and integration with other tools in the modern data stack ecosystem.
The cloud-first approach enables better collaboration and accessibility since data can be shared and processed across multiple teams or locations.
Real-Time Processing vs. Batch Processing
Legacy systems traditionally rely on batch processing, where data is processed in intervals (e.g., daily or weekly). This creates delays in accessing insights and decision-making.
With streaming ETL tools like Materialize or KSQL, modern data stacks process data in real time. Every data point is updated as it's ingested – meaning businesses can react to changes faster.
Materialized queries are critical in modern data stacks, especially in real-time data processing. Unlike traditional querying methods, where raw data is stored and then queried at specific intervals, materialized queries continuously update as data changes.
This means each incoming data point automatically updates a live tally, ensuring that results are always current without the need to re-query large datasets. This method dramatically improves performance in data analytics use cases where real-time insights are crucial.
Scalability and Innovation
A significant challenge with legacy systems is scalability. As data grows, so do the infrastructure requirements, leading to costly upgrades. Moreover, innovation is stifled because new tools or capabilities require substantial integration effort.
The modern data stack is modular and cloud-based and designed for scalability. Whether you're processing data from five sources or fifty, the tools are built to handle growing volumes and complexity.
Who can use a modern data stack?
The beauty of the modern data stack lies in its versatility. It can be tailored to fit the needs of different types of organizations:
Small businesses
Small businesses often struggle with limited budgets and resources, making it hard to invest in expensive infrastructure. With its pay-as-you-go pricing models and cloud-first tools, the modern data stack allows startups and small businesses to scale without significant upfront costs.
Tools like Fivetran and Looker Studio make data management accessible even to non-technical teams, enabling data-driven decision-making early on.
Enterprises
Large enterprises often deal with complex data needs across multiple departments. They require systems that can handle real-time data, high volumes, and multiple data sources.
With a modern data stack, enterprises can optimize their data processes and easily integrate AI, machine learning, and real-time analytics.
Enterprises can also maintain data governance more effectively with modern tools, ensuring compliance with regulations like GDPR.
Data scientists and engineers
The modern data stack provides a sandbox for experimentation for data professionals. With tools like debt for data transformation and Snowflake for cloud storage, data scientists can focus on building models and generating insights without worrying about infrastructure.
The stack's modular nature also means they can experiment with new tools and techniques as their needs evolve.
Non-technical users
Not everyone in an organization is a data expert. With a modern data stack, self-service BI tools like Luzmo allow non-technical users to generate reports and insights without relying on data teams. This democratization of data is one of the key advantages here, as it makes data accessible to everyone.
Key components of a modern data stack
1. Data sources
Modern data stacks connect to multiple data sources, using APIs and connectors to pull data from databases, SaaS platforms, and cloud services. Examples include:
- Databases: Snowflake, Amazon Redshift, MySQL, PostgreSQL, Databricks
- APIs: For custom SaaS products
- Cloud tools: Google Analytics, Salesforce, Hubspot
As we mentioned, legacy systems struggle with scalability. They connect only to a limited number of data sources and process data in batches, which delays insights. This is why businesses are shifting toward modern data stacks, which can connect to various sources and handle real-time data.
2. ETL/Data transformation
Before you can analyze or visualize data, it must be cleaned and structured. The ETL (Extract, Transform, Load) process handles this by transforming raw data into structured formats that are ready for analysis.
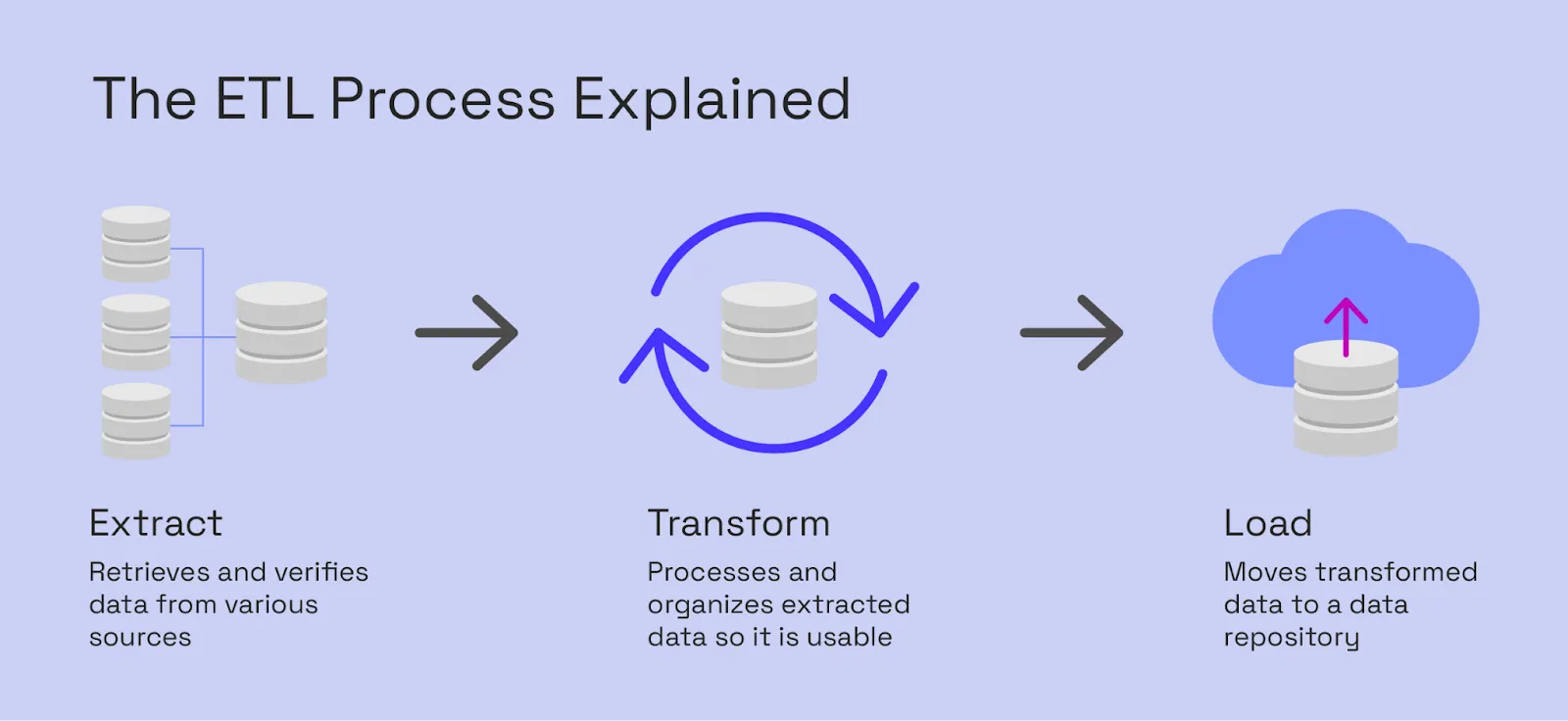
Some of the best ETL tools include:
- Fivetran
- Panoply
- Azure Data Factory
- AWS Glue
Many companies are shifting to ELT, where data is transformed at the destination rather than in transit. This speeds up the process and allows real-time updates.
3. Data lakes and data warehouses
Modern data stacks often include both data lakes and warehouses. Data lakes store large amounts of raw, unstructured data, later refined into smaller, structured datasets in data warehouses. Some popular data lakehouse and warehouse tools are:
- Data lake storage: AWS S3, Azure Blob Storage
- Data processing tools: Athena, BigQuery
Data warehouse tools store clean, structured data. They are more scalable and flexible than traditional on-prem systems, which struggle with large datasets.
A data lakehouse architecture combines the strengths of both data lakes and data warehouses, providing a unified system for handling raw, and unstructured data and clean, structured data.
In a data lakehouse, data can be ingested in its raw form, stored in low-cost lake storage like AWS S3 or Azure Blob Storage, and then transformed and organized into structured data that can be queried quickly through a data warehouse layer.
This architecture allows for greater freedom in handling big data, enabling data science and engineering teams to access cold data (for deep analysis) and hot data (for real-time applications).
The lakehouse provides the best of both worlds: the scale and cost-efficiency of a data lake with the query performance and structure of a data warehouse.
4. Data visualization
The last component of the modern data stack is data visualization, which turns raw numbers into meaningful insights through charts, graphs, and dashboards. Popular tools include:
- Luzmo: For embedded analytics
- Looker Studio: For marketing reporting
- Tableau: For enterprise-level data exploration
In many cases, the only way decision-makers can interact with data is through visualization. Complex data should be easy to understand, even for non-technical users.
Emerging trends in modern data stacks
Streaming ETL and materialized queries
One of the most significant developments in data processing is streaming ETL. Unlike traditional ETL processes that handle data in batches, streaming ETL ingests and processes data in real time. Tools like Materialize and KSQL allow businesses to update query results continuously as new data arrives.
This is particularly useful for applications requiring real-time metrics, such as financial trading, where tools like an online DCF calculator rely on up-to-date market and financial data to support valuation decisions.
AI and Unstructured Data
As AI becomes a critical component of modern business intelligence, the ability to store and process unstructured data (emails, images, voice recordings) is increasingly important.
Tools like embedding/vector stores enable businesses to process unstructured data in ways similar to structured data, providing insights through natural language processing. This opens up new possibilities for AI-driven decision-making and automated workflows.
As AI workloads grow, modern data stacks are being reimagined to handle structured and unstructured data more effectively. With the rise of large language models (LLMs) and natural language queries, companies must rethink how their data stacks process, store, and retrieve information.
While traditional data stacks were primarily focused on structured data, today's workloads require an approach that manages unstructured data such as emails, documents, images, and voice recordings.
Businesses can now answer natural language queries with high accuracy by integrating tools like embedding and vector stores into their modern data stacks.
Benefits of a modern data stack
No vendor lock-in
One of the greatest advantages of a modern data stack is eliminating vendor lock-in, a standard limitation of legacy systems. Unlike traditional platforms, where businesses were forced to rely on a single vendor for all tools, data stacks allow companies to choose the best data platform for each stage of their data engineering workflows.
This adaptability applies to data ingestion, data pipelines, and data analytics, allowing businesses to incorporate open-source or specialized transformation tools tailored to their unique requirements.
For example, a business might select one provider for SQL needs and another for data orchestration or reverse ETL. This composable approach ensures that businesses are never tied to one tool, letting them swap out components as needed without overhauling their entire system.
Easier maintenance
Maintenance is significantly simplified with a modern data stack. Unlike legacy systems, where an issue with one component often means disrupting the entire system, the modular nature of that data stack allows businesses to isolate and address issues within individual tools.
For instance, a problem with a data pipeline or quality metrics can be resolved without affecting the data models or analytics tools that rely on it.
This ease of maintenance is further enhanced by automation and observability tools that provide continuous monitoring of metadata and performance. With these tools, businesses can monitor their data ingestion process, ensuring the data platform remains operational without constant manual intervention.
Faster innovation
A modern data stack accelerates innovation by enabling businesses to adopt new tools and technologies without disrupting existing workflows. Upgrading or replacing a tool in a legacy environment often requires significant rework.
However, with a modern stack, you can easily integrate new data analytics or data science tools as they become available, allowing your teams to experiment with cutting-edge features such as reverse ETL, orchestration, or advanced data integration.
This modular approach promotes rapid functionality improvements, ensuring businesses can leverage new AI, machine learning, and data science developments to create more dynamic data models.
The ability to test and adopt new analytics tools quickly lets companies optimize their data pipelines and create more personalized, data-driven products. As providers offer more open-source and specialized solutions, businesses can continue to innovate at a pace that suits their growth trajectory.
Moreover, with data observability and metadata management tools, companies can maintain full control over their data pipelines while continuously improving data quality.
Conclusion
Legacy systems may have served businesses well in the past, but with the rise of cloud computing, AI, and real-time analytics, they can no longer keep up.
At Luzmo, we specialize in making big data visualization simple and accessible for businesses of all sizes. Whether you're a small business just starting with data or an enterprise looking for advanced analytics, our platform integrates seamlessly into your modern data stack, helping you turn raw data into actionable insights.
Get a free demo of Luzmo today and see how quickly you can unlock the power of your data!
Written by

Ship the future of your data
Let us show you what Luzmo can do for your product.

Leave your e-mail and one of our analytics experts will reach out to you